A few years ago, I was invited to speak at a company’s internal digital summit. Tucked inside my broader presentation, I had a few slides on crawl and indexation issues to remind the attendees that crawling and indexing are essential. However, what started as a brief overview evolved into a frustrating and eye-opening ad hoc breakout session later in the day. It became clear: this industry has a serious blind spot. I’m not sure if it’s arrogance, ignorance, or perhaps both, but it’s beyond ironic that the critical first step in the crawl chain is not given the respect it deserves.
Shortly after, I was contacted by a few companies that had issues with their hreflang tags and engaged me to consult on the matter. It was this very problem, but they and their tech teams did not agree that it was somehow Google’s fault, and they were being penalized for it. I created a video, “Why SEO’s Don’t Respect Crawling and Indexing” (48 minutes), as a rant to send to them, hoping it would explain the bigger picture.
Despite all our talk of the future of AI, rankings, and optimization, most search marketing experts still treat crawling and indexing as someone else’s problem—namely, the search engines’. That mindset is killing performance. It’s wasting resources, frustrating engineers, and eroding our credibility with Google, Bing, and now, AI-driven retrieval engines.
Here’s why it matters—and why we need to rethink everything from crawl stats to XML sitemaps.
Crawling and Indexing Is Expensive (For Everyone)
Crawling and indexing are not free. Google’s data centers consume 15.5 terawatt hours of electricity annually—about the same as all of San Francisco. That’s before AI compute gets factored in. When Google or Bing visits your site, it incurs real energy, infrastructure load, and opportunity costs. Every wasted crawl request is a resource that could have been used more effectively elsewhere.
And yet, most SEOs approach crawling with a “Google should figure it out” mentality. But Google’s not your janitor. It’s a search engine with finite resources and growing pressure to be efficient.
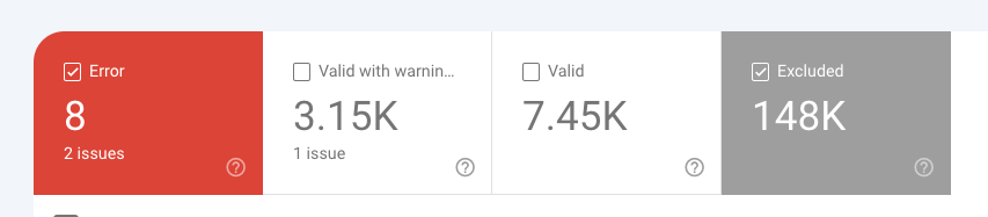
Just look at these numbers:
- 158,000 URLs discovered
- 148,000 excluded
- Only 7,450 indexed
- 98% of crawl effort wasted
If a website wastes a crawler’s time 98% of the time, why should that crawler come back?
Why Search Console Exists: It’s Not Charity
Search Console wasn’t created out of Google’s and Bing’s goodwill. Why would they spend millions of dollars to build the system, store the data, and present reports? It’s a tool to help you identify and fix problems that cost them time and money.
Every exclusion, redirect, soft 404, or mismatch in your sitemap is an inefficiency. Search engines provide the data, hoping you’ll take action. However, most marketers view it as a weather report instead of a system health dashboard.
If your average Search Console report shows 3 to 5 bad URLs for every good one, you don’t have a crawl issue—you have a quality and alignment issue.
The Myth of the Infinite Crawl Budget
“Unless you have a million pages, you don’t have to worry about crawl budget.” That is what many SEOs will tell you when you mention crawl budget or the need to work on crawl efficiency. That’s flat wrong.
This is a slide from 20 years ago. The site was supposed to have 50 million URLs. The in-house XML sitemap only listed 12.5 million URLs (where are the other 35.5 million) and from those on the list, there were 14.6 million errors. I can safely say there is really no reason other than massive brand awareness for any search engine to try and figure out this mess.
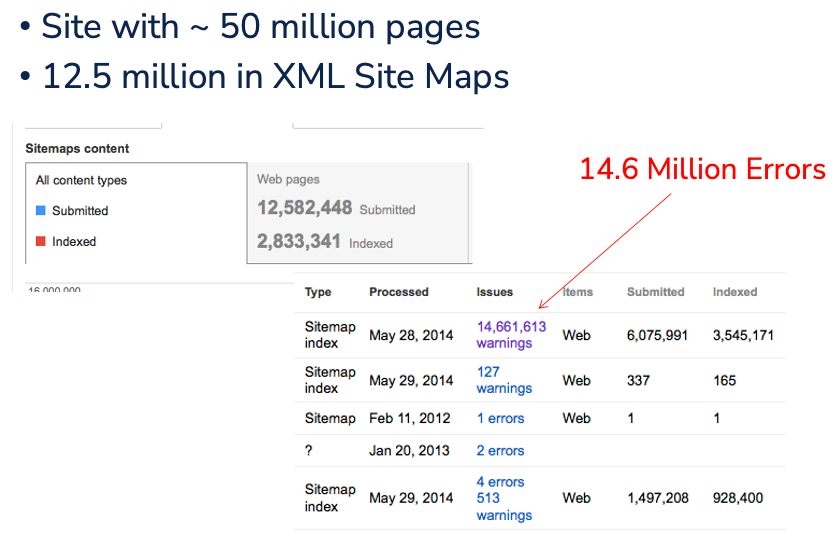
Every site has a crawl ceiling, whether you refer to it as a budget, capacity, or value threshold. Google has to decide whether crawling your site is worth the electricity and infrastructure cost. That decision is made based on two things:
- Crawl Capacity: Can Your Site Handle It? (Speed, error rates, server load)
- Crawl Demand: Is the content worth it? (Freshness, uniqueness, popularity, value)
If your site is slow, error-prone, or filled with low-value or duplicated content, Google will back off. The era of indiscriminate web crawling will come to an end. As infrastructure costs mount, search engines and AI companies will shift from a “crawl everything” to a “crawl selectively” approach. This transformation, catalyzed by growing resource constraints, demands that content creators and brands optimize for crawl-worthiness or risk digital invisibility.
Crawl Waste: The Hidden Cancer
Crawling and indexing are VERY EXPENSIVE, so search engines NEED to become more efficient in their efforts. We are seeing this with Bing’s launch of IndexNow and Cloudflare’s Crawler Hints.
Let’s discuss what’s quietly impacting your performance at key data points related to crawl resource waste.
- According to Cloudflare, 55% of pages requested by Google haven’t materially changed.
- According to Google, 30% of discovered URLs are flagged as spam or junk.
- Most sitemaps are garbage: they include 404s, noindex pages, canonicalized duplicates, or forbidden URLs
- Dynamic e-commerce filters can create hundreds of junk variations per product.
- Crawl stat reports are ignored, buried in “Settings,” while teams keep chasing keyword ranking wins rather than error reductions.
This isn’t just technical SEO negligence, it’s operational malpractice. The foundational layers are rotting, and we’re painting the walls.
Real-World Gaps You Probably Have
In hundreds of audits, I’ve seen the same patterns repeat where there is no real coordination to ensure maximum indexing. The following is an analysis from a multinational where the agency did not find any crawling or indexing issues.
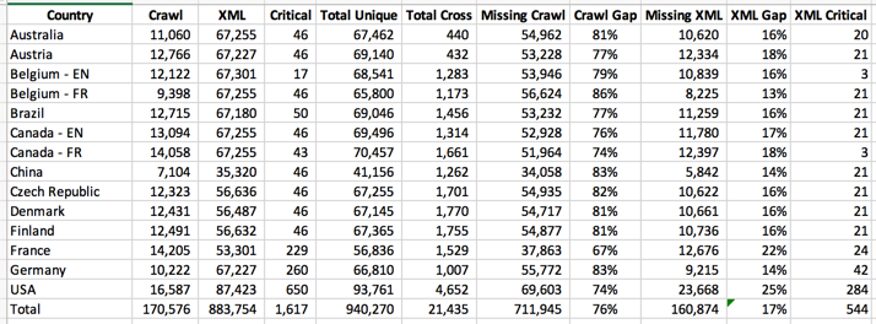
- Only 6.5% of pages found in a crawl were present in sitemaps
- 76% of sitemap pages were not crawlable
- 34% of business-critical pages were missing from sitemaps entirely
- Sitemap URLs pointed to pages with 403s, 404s, blocked robots, or noindex tags
- Parameter-based pages submitted with no canonical logic or consistent URL structure
- Case-sensitive mismatches (e.g.,
/Help/vs/help/) killing re-indexing
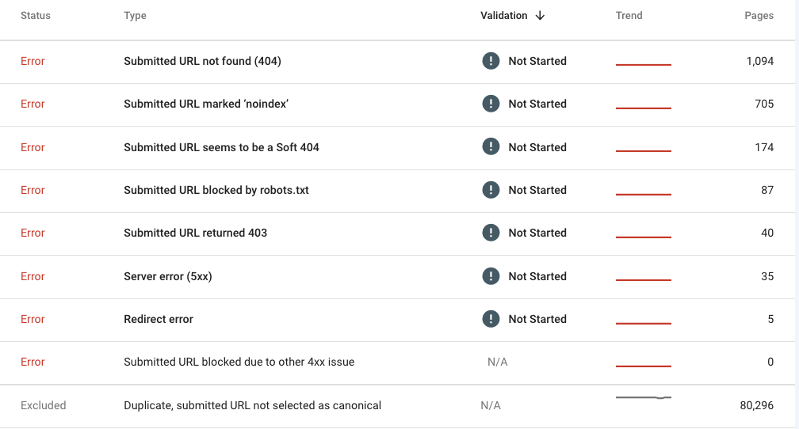
In one case, simply standardizing case sensitivity (big “G” vs little “g”) reindexed 98% of the help center resulted in 2,000% increase in visits and boosted customer satisfaction by 30 points in post-visit surveys.

The DevOps Gap: Hidden Server Fails
SEOs rarely talk to backend engineers. And that’s a problem.
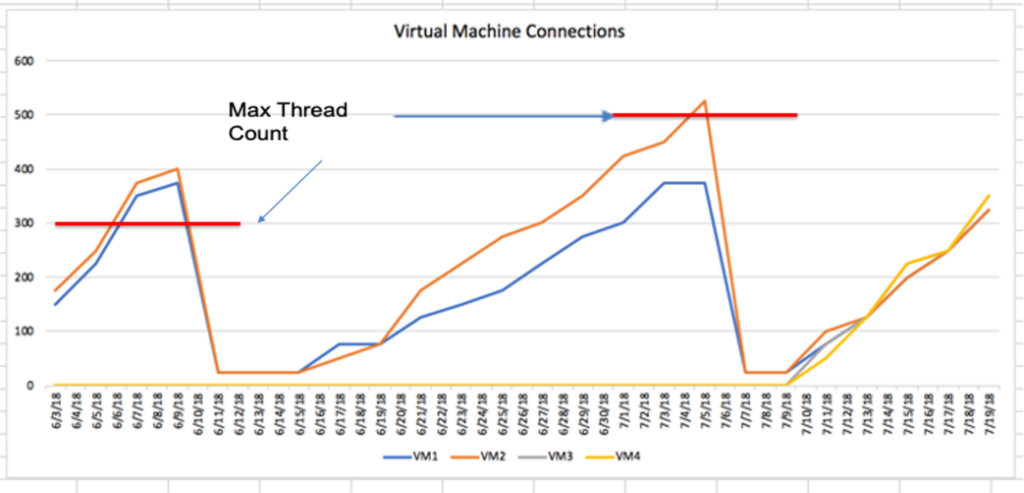
I’ve seen massive sites migrate to HTTPS, beg Google to crawl them, and then throttle crawlers unknowingly because:
- Only 2 out of 4 app servers were running
- Max thread counts were exceeded under crawl load
- Search engines got hit with 500 errors and backed off for days
On paper, everything looked fine. The Server team showed reports that they barely dented their Akamai capacity when I asked for the app server logs; they stated there was no correlation between the 500 error and the app servers. Until I explained that the app server was generating the dynamic information presented on the pages. When they opened the logs, the problem was immediately spotted. Only two of the four app servers were enabled, and both had low thread thresholds. Trying to get Google to recrawl millions of new pages was overloading the internal servers.
The Fix List (That No One Wants to Do)
Here’s what we all should be doing but often avoid:
Crawl Efficiency
- Prioritize pages that are fast, structured, canonical, and unique
- Block junk parameters and dynamic filters with robots.txt or consistent canonical rules
- Use
indexifembeddedornoindexwith intent - Leverage
hreflangclusters to trigger meaningful market-based crawling
Sitemap Hygiene
- Only include 200-response, indexable URLs
- Match crawl, sitemap, and priority pages—track the delta
- Deduplicate, ping, and validate URLs weekly
- Don’t rely on CMS auto-generation—most are broken
Infrastructure Awareness
- Know your app servers, their loads, thread limits, and failover behavior
- Monitor Crawl Stats for spikes, dips, and surges in response codes
- Log server-side error sources: DevOps needs to know what’s killing your crawl
Rendering & Indexability
- Render key content server-side or use trusted prerender services
- Ensure SEO-critical markup (like hreflang or schema) is present in both raw and rendered HTML
- Minimize DOM complexity and push meaningful content higher in the HTML
The Future Is Resource-Aware SEO
With Google, Bing, and AI engines shifting to intent-driven and resource-aware systems, the traditional “spray-and-pray” indexing model is obsolete. Tools like Cloudflare’s Crawl Hints and Bing’s IndexNow aren’t optional—they’re previews of where search is going.
You want to be indexed? Prove it’s worth the cost.
Final Thought: Search Engines Are Not Your Interns
Search engines owe you nothing. They are not obligated to crawl your 4 million thin variations or to guess which URL you want indexed. If you submit garbage, they’ll skip you. If your systems are broken, they’ll quietly stop visiting.
You don’t get traffic from content that isn’t crawled. You don’t get conversions from content that isn’t indexed. It’s that simple.
So, to all the SEOs who think crawl health is boring, start respecting the fundamentals. Because in the age of AI, the price of inefficiency is invisibility.