A Query Is Not Just Words
For decades, search engines treated a query as a handful of words to match. Type “best CD rates” and the machine would go hunting for pages with those exact words.

That era is coming to an end.
Today, a query is more than a string of words. It’s a set of instructions:
- “Best” signals a ranking must be calculated.
- “CD” must be resolved to the proper context (finance, not a music delivery device).
- “Rates” demands a numeric measurement (APY).
In other words, a modern query isn’t just something to find. It’s something to interpret, structure, and satisfy.
This is why we can’t treat “best CD rates” as just three words — it’s a contract between the user and the platform. The system must define, measure, and rank before it can answer.
This article explains, step by step, how a modern AI search system interprets the query “best CD rates” and produces a ranked, synthesized answer.
I chose this deceptively simple query because it offers a great example of the various steps necessary to return a synthesized answer.
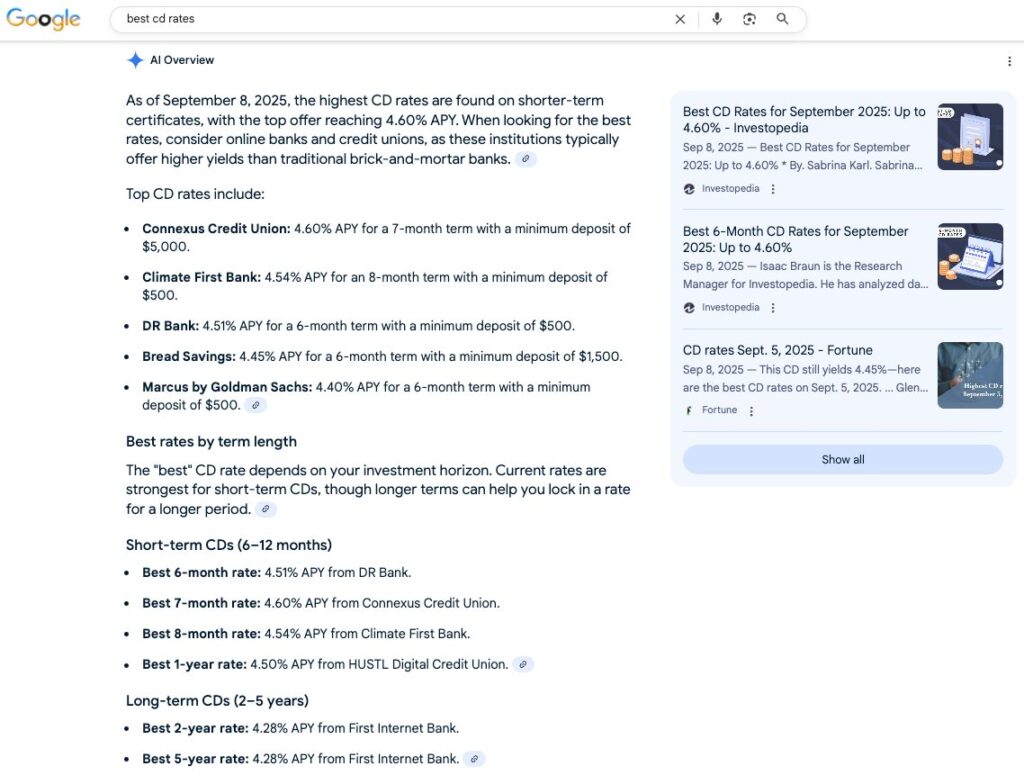
Screenshot Context
Google’s live output for “Best CD rates” (as of September 9, 2025) included:
- Timestamped overview: “As of September 8, 2025, the highest CD rates are found on shorter-term certificates …”
- Ranked list with APYs, terms, and minimum deposits
- Grouped by term lengths (6-month, 7-month, 8-month, 1-year, 2-year, 5-year).
- Essential factors: minimum deposits, penalties, credit union eligibility, and rate stability.
“That live output is the end product. Let’s now walk backward through the pipeline to see exactly how the system got there, one step at a time.”
Step 0 – Pre-Processing & Context Setup
Purpose: Normalize the query and set the right expectations before any deeper processing. This step establishes the rules of the playing field (currency, regulator norms, measurement units, recency). Without this, “rates” could mean different things in different countries.
Actions:
- Normalize the query text: Handle case, punctuation, and spacing → “Best CD rates.”
- Detect language/region: Check interface language, IP, or past settings.
- Apply safe personalization (if allowed): Prior finance queries tilt “CD” toward banking.
- Infer context: Financial query, not music.
Why it matters:
- In the U.S., “rates” implies APY (Annual Percentage Yield) for CDs, with FDIC/NCUA protection as the trust baseline.
- In the UK, the same query would expect AER (Annual Equivalent Rate) and FSCS protection.
- In Japan, it would expect yen-based rates from local banks.
Without this pre-processing, the system might:
- Return the wrong measurement system (AER instead of APY).
- Miss required regulatory framing (e.g., FDIC vs FSCS).
- Confuse CDs with music discs instead of certificates of deposit.
Evidence: Google’s answer explicitly uses “certificates” and lists APYs in percentages, consistent with U.S. banking norms. It also includes a freshness timestamp (“As of September 8, 2025”), proving recency is part of the setup.
Old vs. New: Old engines did minimal normalization and relied on literal matches. Modern systems establish contextual defaults upfront to make sure every later step builds on the right ground rules.
Step 1 – Role Tagging — Assigning Jobs to Words
Purpose: Turn a loose phrase into an interpretable request by assigning functional roles. (How the System Determines the Meaning of Each Word). Where the words are transformed into instructions for the next steps of processing.
Inputs: Canonicalized query tokens: best, CD, rates.
When you type “Best CD rates”, the AI doesn’t just see three words in a row. It assigns each piece of the query a role in the sentence so it can interpret the searcher’s intent:
Action:
- “Best” → Superlative. implies the user expects ranking/comparison of the different options. Therefore, the system marks this as a request for a ranking or comparison, not just information. You don’t want a definition of CDs — you want the top option.
- “CD” → Domain object. Initially, the system classifies “CD” as an Ambiguous Subject. The model considers multiple possible meanings (compact disc? certificate of deposit?) and uses context from the next word (“rates”) to lock in the finance definition.
- “Rates” → Measurement. Here, “rate” implies the need for a numeric value — and in finance, that means APY (Annual Percentage Yield).
👉 What’s really happening: Behind the scenes, the system is essentially tagging your query with metadata:
Evidence: Google doesn’t just explain CDs; it delivers a ranked list with numbers.
- Example: “Connexus Credit Union: 4.60% APY … DR Bank: 4.51% APY …” This proves “best” triggered a ranking response.
Outputs: A role‑annotated query structure: Superlative(best) · Subject(CD:ambiguous) · Measurement(rates→APY).
This invisible annotation is what makes the rest of the process possible. Without it, the engine would just return any page that mentions the exact words, which is precisely how old Google worked.
Why it matters: These tags define the kind of answer required: numbers, comparability, and ranking.
How & Why: How = model applies functional labels (superlative, subject, measurement). Why = tells the system what kind of answer is required (numbers + ranking, not just a definition).
Old vs. New: Old search treated “best/CD/rates” as plain words; new systems treat them as instructions.
Contrast with Old Google:
- Old: “Best CD rates” → look up “best,” “CD,” “rates” in the index and pull pages with those words.
- New: “Best CD rates” → understand what role each word plays, then filter only the content that can actually deliver on those roles (e.g., pages with numbers representing APY).
👉 Analogy: Think of role tagging like casting a play. In old search, every word was just a random actor on stage. In AI search, each word is given a role in the story — the hero (superlative), the subject (financial CD), the scorecard (APY) — so the system knows how to direct the performance.
Step 2 – Tokenization — Preparing Units for Computation
Purpose: Break the query into processable units.
Inputs: Role‑annotated text.
Actions:
- Split into tokens: [best] [CD] [rates] (plus hidden boundary tokens).
- Map to vocabulary IDs for downstream models.
Outputs: Token sequence ready for modeling.
Evidence: The answer mirrors the token structure:
- Superlative → “highest,” “best.”
- Subject → “certificate of deposit.”
- Measurement → APY numbers in percent form.
Why it matters: Tokens are the substrate for embeddings and attention.
Old vs. New: Both tokenize, but only modern systems couple tokens with roles and later semantics.
Step 3 – Disambiguation via Embeddings — Locking the Domain
Purpose: Resolve any ambiguous terms – In this case, the meaning of “CD” in financial terms.
Inputs: Token sequence + roles + context (presence of “rates”, locale = US finance).
Actions:
- Generate embeddings (meaning vectors) for tokens and the whole query.
- Compare against domain spaces:
- CD (music) neighborhood vs. CD (financial)/interest‑rate neighborhood.
- CD (music) neighborhood vs. CD (financial)/interest‑rate neighborhood.
- Use context (“rates”), locale (US), and recent user intent to choose a certificate of deposit as the true meaning of CD.
Evidence: The output states: “shorter-term certificates …” and provides APYs. No mention of music CDs.
Outputs: Disambiguated subject: CD → Certificate of Deposit.
Why it matters: Prevents irrelevant retrieval (albums) and enables finance-specific rules, such as APY.
Old vs. New: Old engines often returned mixed intents; modern systems commit to a domain early.
Step 4 – Semantic Query Expansion — Say It the Ways the Web Says It
Purpose: Express the user’s meaning in variant phrasings to improve recall. Users and publishers often phrase things differently — “best CD rates” vs “highest APY” vs “top yields.”
Inputs: Disambiguated query meaning.
Actions:
- Expand concepts: “best CD rates” → “highest APY for certificates of deposit”, “top 12‑month CD yields”, “promotional CD APY”.
- Expand synonyms: best↔highest/top; rates↔yields/returns; CD↔certificate of deposit.
- Generate retrieval queries for the semantic index.
Outputs: A small set of meaning‑equivalent queries.
Evidence: Google’s output uses these expansions:
- “highest CD rates … top offer reaching 4.60% … best 6-month rate … best 7-month rate …”
Why it matters: Retrieves high‑quality pages that don’t use your exact words.
Old vs. New: Old search needed literal overlaps; modern search targets concept overlap.
Step 5 – Eligibility Gates — What Content Qualifies (filters)
Purpose: Prune out anything that cannot enter the competition by enforcing context correctness/relevance and data sufficiency before ranking.
Inputs: Candidate pages/snippets from semantic retrieval.
Actions: Apply pass/fail eligibility gates:
- Context Gate: Page must be about banking CDs.
- What it asks: Is “CD” the financial product (not music), and is this page about banking CDs?
- Where the criteria come from (provenance):
- User intent history: Queries with rates + CD overwhelmingly mean finance.
- Step 0/1/3 signals: Locale (US) → APY norms; role tagging says “measurement”; embeddings resolve “CD”→finance.
- Validator precedent: Banks/aggregators label these pages “CD rates,” “Certificate of Deposit.”
- Operational checks (sub-steps):
- Look for finance lexicon (APY, term, early withdrawal penalty, FDIC/NCUA).
- Penalize/deny if strong music/retail signals (album, artist, tracks).
- Edge cases: Mixed pages (education pages that define CDs but show no rates) → fail Context or get routed to info answers, not “best” lists.
- Pass example: “Certificate of Deposit (CD) Rates — 6, 12, 24 months — APY%”
- Fail example: “Top CD album prices” or “What is a CD?” with no products.
- Measurement Gate: Page must expose numeric APY (as text/structured data).
- What it asks: Does the page expose a numeric rate for the CD(s) in machine-readable text?
- Where the criteria come from (provenance):
- User intent history: “rates” requires numbers.
- Regulatory/industry norms: APY disclosure in the US.
- Validator precedent: Aggregators always include numeric APY.
- Operational checks:
- Extract APY as
%(not images). - Reject “great rates,” “as low as,” “call for rates” with no number.
- Extract APY as
- Edge cases: If the rate is shown only in an image or PDF without extractable text → usually fail (or low confidence).
- Pass: “4.50% APY”
- Fail: “Competitive rates available”
- Comparability Gate: Must specify term length (e.g., 6/12/24 months).
- What it asks: Does the content specify a time horizon for the rate so offers can be compared on equal footing?
- Without a term length, a “4.5% APY” could mean 6 months or 5 years — not comparable.
- With a term length, the system can group offers into buckets (e.g., 6-month, 12-month, 24-month) and rank them fairly.
- Comparability is a baseline requirement triggered earlier by the superlative role (“best”) + the product schema for CDs. The system knows from domain knowledge that term length is the core dimension that makes CD APYs comparable. So it demands term before it defines the precise “best” formula. The system’s job is to lock the token into the right context space before moving forward.
- Where the criteria come from (provenance):
- Role tagging (Step 1): “Best” → ranking required.
- Product schema (learned/domain): A CD has attributes {term_length, APY, min_deposit, penalties, availability}.
- Entity/knowledge graph awareness: The system doesn’t just see “CD” as text. It recognizes “CD = certificate of deposit” as an object in its financial knowledge graph. That graph encodes required attributes — rate in APY, duration/term, minimum deposit, and FDIC/NCUA coverage. Because of this entity model, the system recognizes that comparability requires term length (6 months vs. 5 years) and trust requires disclosure of insurance and conditions.
- Operational checks:
- Require term length for each APY (e.g., 6m, 12m, 24m).
- If the page lists a single “bank APY” with no term → fail.
- If multiple terms exist but the APY is not tied to a term → fail.
- Edge cases: “Ladder” pages with blended messaging; odd terms (7/8 months) are fine if clearly labeled.
- Pass: “6-month: 4.51% APY; 12-month: 4.45% APY”
- Fail: “Our CD APY is 4.5%” (no term stated)
- What it asks: Does the content specify a time horizon for the rate so offers can be compared on equal footing?
- Freshness Gate: Rates must be current (visible date or verifiable update signal).
- What it asks: Are the rates recent (not historical/stale)?
- Where the criteria come from (provenance):
- User expectation: “Best” implies now, not last year.
- Platform incentives: Trust/liability; show timely info.
- Validator precedent: Aggregators display “as of” dates.
- Operational checks:
- Find the explicit effective date or “as of” near the table.
- If no date, infer from crawl/update signals (low confidence).
- Enforce a recency window (e.g., days/weeks) for finance.
- Edge cases: Bank pages that update daily but omit a date → may pass with low confidence or be demoted.
- Pass: “Rates effective: Sep 8, 2025”
- Fail: “2023 CD rates” still ranking with no updates
- Availability Gate: Declare nationwide vs. state‑limited vs. membership‑only.
- What it asks: Is the scope/eligibility declared (nationwide vs. state-limited vs. membership-only credit unions)?
- Where the criteria come from (provenance):
- Actionability norm: Users must know if they can act on it.
- Regulatory/industry: CUs require membership; some banks are state-limited.
- Validator precedent: Aggregators tag “nationwide,” “membership required.”
- Operational checks:
- Extract availability cues:
- “Available nationwide” / “Residents of X only” / “Membership required”
- Classify:
nationwide|state_limited|membership_only|branch_only|unknown - Gate rule:
- If membership_only → require a clear path (e.g., “join via $5 donation”).
- If state_limited → include but annotate; may rank lower for generic queries.
- If unknown → include with penalty or exclude (policy-dependent).
- Extract availability cues:
- Edge cases: Hidden eligibility in PDFs/footnotes → likely fail or be penalized.
- Pass: “Membership required (eligible via ABC association, $5 donation).”
- Fail: “Top rate!” with no indication it’s local only.
- Qualification Gate: Clear minimum deposit/tier requirements.
- What it asks: Are the minimum deposit (and tier conditions) clearly stated for the APY shown?
- Where the criteria come from (provenance):
- Consumer fairness norm: A 5% APY at $25,000 minimum is not comparable to 5% at $500.
- Regulators/aggregators require minimums next to rates.
- Operational checks:
- Extract min_deposit per APY per term.
- If tiered, tie APY to the correct tier (“4.60% APY for $5,000+”).
- If new-money only, flag as restriction (used later in tie-breakers).
- Edge cases: APY listed but min deposit buried in disclosures → may pass with lower confidence.
- Pass: “4.60% APY (min $5,000) — 7 months”
- Fail: “4.60% APY — 7 months” (no minimum stated)
- Trust/Quality Gate: Credible source (bank/credit union site, reputable aggregator/publisher; FDIC/NCUA signals).
- What it asks: Is the institution/site trustworthy and is the data consistent with other sources?
- Where the criteria come from (provenance):
- Platform incentives: Liability avoidance; preserve user trust.
- Regulatory directories: FDIC/NCUA lookups.
- Validator precedent: Bankrate/NerdWallet inclusion; cross-source agreement.
- Operational checks (layered):
- Source type: Official bank/CU site? Known aggregator/publisher? Unknown blog?
- Reg/identity checks: FDIC/NCUA presence; HTTPS; corporate footprint.
- Cross-corroboration: Does APY/term/min match aggregators or vice versa?
- Quality heuristics: No “up to” bait, clear disclosures, accessible content (no images-only rates).
- Edge cases: New entrants with great rates but limited footprint → may be included with caution or deprioritized without corroboration.
- Pass: Official bank page + aggregator corroboration + FDIC badge.
- Fail: Thin affiliate blog with mismatched numbers.
Outputs: A shortlist of eligible, structured candidates.
Evidence: Every item listed includes all required fields:
- Connexus: 4.60% APY, 7-month term, $5,000 min deposit.
- Climate First: 4.54% APY, 8-month term, $500 min deposit.
No vague “great rates” claims. All entries passed the gates.
Why it matters: Stops vague, outdated, or misleading pages from entering the ranking pool.
Old vs. New: Old results were lists of lists and pages that lacked numbers or had incorrect intent; modern systems prioritize pruning first.
Where do these baseline requirements come from?
They’re not invented on the spot. The system blends user intent history, regulatory/industry norms, product schemas learned from the web, aggregator field conventions, and platform incentives (compute, friction, profitability). That’s what sets the “bouncer’s checklist” for CDs: APY present, term stated, current date, availability declared, minimums disclosed, and a credible source.
“Most AI systems blend live aggregator feeds, licensed data streams, and model memory. If your info isn’t present in those, you’re invisible.”
would answer a big hidden question.
Step 6 – Superlative Resolution — Defining “Best”
Purpose: Turn “best” into a scoring formula. Once you’ve got qualified contenders, you define the “rules of the game” to rank them. — Defining “Best”
Inputs: Normalized table + domain heuristics.
Actions:
- Define Primary metric: Maximize APY within each term bucket.
- Tie‑breakers (predictive heuristics):
- Prefer lower minimum deposit.
- Prefer nationwide over restricted membership, all else equal.
- Prefer clearer/less severe early withdrawal penalties.
- Prefer more recent effective dates.
- Optionally weight institution reputation.
- Prefer lower minimum deposit.
Outputs: A ranked list per term bucket.
Evidence:
- “Best 6-month rate: 4.51% … Best 7-month rate: 4.60% … Best 8-month rate: 4.54% …”
- Banding by term length demonstrates that the system applies comparability logic.
Why it matters: “Best” becomes an actual rule set, not a vibe and ranking requires numbers and attributes, not prose.
Old vs. New: Old engines ignored superlatives in ranking; modern systems compute them.
Why the Order Matters
It may seem counterintuitive that eligibility filtering (Step 5) comes before defining “best” (Step 6). But the two serve different purposes. Eligibility Gates act like a bouncer at the door — they enforce baseline requirements so only valid, comparable offers enter the pool. At this stage, the system doesn’t care who wins, only that every offer has the minimum attributes required: an APY, a term length, a freshness signal, and a deposit requirement. Without these, no fair comparison is possible.
But where did the bouncer get the criteria?
The baseline requirements aren’t invented on the spot. They’re drawn from learned patterns in user intent (e.g., people searching for “rates” expect numbers and timeframes), regulatory norms (FDIC/NCUA in the U.S., FSCS in the U.K.), and historical data on what qualifies as a valid offer. In other words, the system has been trained — through billions of past interactions and authoritative data — to know what fields are mandatory before ranking can happen.
Superlative Resolution then takes over. Once the pool is filtered, the “referee” defines and applies the scoring formula — in this case, “highest APY within each term bucket, with tie-breakers for deposit minimums, availability, and penalties.” Eligibility ensures the data is usable; superlatives define how it will be judged.
Baseline vs. Ranking Criteria
| Stage | Question Asked | Examples of Requirements | Purpose | Analogy |
|---|---|---|---|---|
| Baseline (Eligibility Gates) | Does this offer have the minimum attributes to even enter the pool? | – APY is present and numeric – Term length specified (6/12/24 months) – Effective date / freshness – Minimum deposit disclosed – Availability (nationwide, state, or membership) – Credible/trusted source (bank, CU, aggregator) | Ensure only valid, comparable offers are considered. Prevents vague, stale, or misleading entries. | Bouncer – only lets people in who meet dress code, age, ID check. |
| Ranking (Superlative Resolution) | Among qualified offers, who is the “best”? | – Highest APY within term bucket – Tie-breakers: lower min deposit, broader availability, fewer penalties – Recency priority – Optional weight for brand trust/reputation | Define “best” mathematically and apply rules of the game to determine winners. | Referee – applies the rules once the players are on the field. |
Step 7 – Data Extraction — Turning Pages into Rows
Purpose: Extract structured attributes from documents.
Inputs: Shortlisted pages.
Action: From bank/aggregator pages, pull:
- APY (e.g., 5.15%).
- Term (e.g., 12 months).
- Minimum deposit (e.g., $1,000).
- Availability (nationwide / state / membership).
- Effective date / last updated.
- Early withdrawal penalty (if stated).
- Notes (promo/new‑money‑only).
Outputs: Structured records (one row per offer).
Evidence:
- “Minimum deposit of $500 … minimum deposit of $5,000 … membership required …”
Why it matters: Ranking requires numbers and attributes, not prose.
Old vs. New: Old = rank whole pages. New = extract offers from them.
Step 8 – Normalization — Make It Apples‑to‑Apples
Purpose: Standardize fields for comparability and fairness.
Inputs: Extracted rows.
Actions:
- Normalize units to APY %; ensure consistent compounding assumption.
- Bucket by term (6/12/24/36/60 months) to avoid cross‑term distortion.
- Canonicalize currency (USD) and insurer context (FDIC/NCUA badges as metadata, not score).
- Standardize availability labels and deposit tiers.
Outputs: Clean table ready for scoring.
Evidence: Output splits short-term vs. long-term CDs, with APYs aligned within buckets.
Why it matters: Prevents a 6‑month promo from being compared against a 5‑year APY.
Old vs. New: Old engines didn’t normalize; users did the work by clicking around.
Step 9 – Ranking & Tie-Breaking
Purpose: Apply the scoring formula.
Inputs: Ranked rows + multiple sources for the same offer.
Action: Rank by APY, then resolve ties with min deposit, availability, freshness.
Evidence:
- Connexus wins 7-month category (4.60% beats 4.54%).
- Where APYs tie, Google surfaces the bank with better availability or reputation.
Old vs. New: Old = link popularity. New = offer-level ranking.
Step 9b – De‑duplication & Conflict Resolution
Purpose: Clean noisy signals and reconcile inconsistent facts.
Inputs: Ranked rows + multiple sources for the same offer.
Actions:
- Merge duplicates (same bank/term seen on aggregators and bank site).
- Prefer the source of truth (bank page) when the aggregator conflicts.
- Flag/discount teaser “up to” rates or hidden conditions.
Outputs: Final, conflict‑resolved ranking per term.
Why it matters: Avoids double‑counting and incorrect winners.
Old vs. New: Old engines left conflicts to users; modern systems reconcile before answering.
Step 10 – Answer Synthesis — Writing the Mini Report
Purpose: Present a useful, auditable response.
Inputs: Final rankings + metadata.
Actions:
- Compose a short overview (“highest CD rates are found on shorter-term certificates …”).
- List top offers per bucket with APY, term, institution, minimum deposit, and availability.
- Add timestamp (e.g., “As of Sep 8, 2025”).
- Add context: deposit requirements, penalties, and credit union eligibility.
- Provide citations/links for verification.
- Optionally include disclaimers for promos, membership requirements, and penalties.
Outputs: A readable summary plus verifiable sources.
Evidence: Google’s output contains all of these elements verbatim.
Why it matters: Converts data into a decision‑ready answer.
Old vs. New: Old = 10 blue links. New = curated, ranked, explained.
Step 11 – Guardrails & Edge Cases
Purpose: Reduce risk of misleading or stale answers.
Checks:
- Freshness floor: Do not surface rates older than a threshold.
- Ambiguity fallback: If APY or term is missing, omit from ranked winners; optionally include in “also noted” with caveat.
- Localization: If the user adds “near me,” pivot to local availability sort.
- Safety: Avoid hallucinating precise APYs when no verifiable data is available; prefer guidance over guesses.
Evidence in Output:
- Timestamp for freshness.
- Membership caveats: “Credit union eligibility …”
- Penalties: “penalty is equivalent to three months of interest …”
- Market context: “CD rates have been declining in 2025 … lock in now.”
These details show the system is not only ranking but also warning and guiding.
“What if nothing passes the gates?” If nothing meets the criteria, the system falls back to a general explainer of CDs or outdated averages instead of listing offers.
Why Content Creators Must Care
This step-by-step journey proves that AI search engines don’t just match words. They:
- Tag roles.
- Resolve ambiguity.
- Expand semantically.
- Apply eligibility gates.
- Extract structured data.
- Normalize offers.
- Define “best” mathematically.
- Synthesize an answer.
If your content doesn’t provide all the scoring elements, such as APYs, term lengths, minimum deposits, freshness dates, and trust signals, in machine-readable form, you won’t pass the gates.
The result? You’ll vanish from the “best CD rates” answer box, even if your product is competitive.
👉 Old SEO was about keywords. New SEO is about eligibility and structure.
Beyond Keywords: Why This Changes the Game
The more profound lesson here is that queries are no longer casual strings of text. They are contracts between the user and the platform.
- When you type “best CD rates,” you’re implicitly demanding: “Show me ranked, current APY numbers, normalized by term length, with qualifiers like deposit minimums and availability.”
- The platform enforces that demand by running every candidate page through roles, gates, extraction, normalization, and ranking.
- Only the content that survives that gauntlet gets written into the final answer.
This is why businesses must think differently:
- Old SEO: Sprinkle in the right keywords and chase backlinks.
- New AI SEO: Provide structured, explicit, comparable data that machines can calculate with.
Superlatives are the toughest test. If your content can’t support the definition of “best,” it won’t even be eligible. But if you can pass that bar, you’ll also surface strongly for simpler informational queries.
The takeaway is simple but urgent: understand how your content is interpreted by machines, not just how it reads to humans. That’s what determines whether you appear in the answers that matter.
In this article, we walked through the entire journey of how a query like “best CD rates” becomes a structured, synthesized answer. But one stage deserves its own spotlight: the Eligibility Gates. These hidden filters decide whether your content even makes it into the race. In the follow-up article, I break down each gate in detail, show how Google applied them in the best CD rates answer, and explain why passing them is now the most critical requirement for visibility.
In this article, we mapped the full journey of how a query like “best CD rates” turns into a synthesized AI answer. But one stage deserves a closer look: the Eligibility Gates — the hidden filters that decide whether your content even makes it into the race.
I break those down in detail in my follow-up article, Eligibility Gates: The Hidden Filters Behind AI Answers. For more context on how AI balances computed vs. curated context, you can also read my Substack piece: Computed Context vs. Curated Context.